

🗞️ Data Digest | Issue #25: Why Small Language Models (SLMs) + Edge Devices are the Future of AI
A Writeup of My Talk from Dallas Software Developers Group "A Night Of AI" Meetup

Earlier this week, I attended the Dallas Software Developers Group “A Night Of AI” Meetup and the energy in the room was electric! I came to speak about the future of small language models and edge AI! The talk was so well received that I thought it only natural that I release the slides and create a writeup of it for others to read and use for research!
For years, that future has been defined by one thing: scale. We’ve been in the era of the Large Language Model, or LLM, where bigger models, trained on more data, yielded more general intelligence.
But as I told the developers in the room, that era is hitting a wall. I’m convinced that the next wave of AI won’t be defined by how big it is, but by how small, fast, and local it can be. The future of ubiquitous, personalized, and truly intelligent computing belongs to Small Language Models (SLMs) and the edge device(consumer devices like smartphones, smart speakers, and laptops, as well as industrial and network equipment such as routers, gateways, sensors, and IoT devices).
The Quest for General Intelligence (and its Cost)
Before we talk about the future of SLMs, let’s acknowledge the present with LLMs.
Large Language Models were created with an ambitious goal in mind, which is to emulate human intelligence across a broad set of domains. They’re the reason you can ask ChatGPT about a random topic like underwater basket weaving and have it draw parallels to a completely unrelated subject like the greatest popstars of all time. The reason for these capabilities starts with the trillions of tokens of training data sourced from the entire internet (webpages, books, code) and private curated collections. This massive scale, built on the Transformer architecture, has given us unprecedented capabilities in complex reasoning, content generation, and coding assistance. It is the foundation of the current AI revolution.
But this power comes with a cost in many different ways, and it’s hitting a wall when we talk about ubiquitous, real-world deployment. That wall is built on three pillars: Latency, Cost, and Privacy.
Latency: Most LLMs run on cloud infrastructure(whether neoclouds or popular cloud services). Every single interaction with an LLM requires a round-trip to a massive data center, which takes time to complete. We’ve all experienced that weird wait time where we are waiting for ChatGPT or Gemini to respond to our request. After a few seconds, we want to switch over to another tab or try another chatbot assistant. For real-time applications, this latency is a killer.
Cost: LLMs also costs a fortune in compute. The majority of this is in inference with generating responses for users. The costs rack up even more when dealing with reasoning models, making it unsustainable at global scale. To paint the picture, one major AI player reportedly spent $12 billion on Azure in inference compute alone in the last seven calendar quarters. Its implied revenue for the period was only about $7 billion.
Privacy: Lastly, LLMs are not privacy friendly. When critical data is fed to an LLM, that information is sent to the cloud, creating massive compliance and security risks. This is not good for healthcare and finance.
With LLMs, we are trading performance for centralization, and that is a bottleneck we must break.
The Rise of the SLM: Smarter, Not Smaller
SLMs, as implied by their name, are much smaller than LLMs and typically only go up to 10 billion parameters. They are trained on data from specific domains whereas LLMs emulate intelligence on a wider level.
The breakthrough is the rebuttal of the old scaling laws where the more model parameters, compute, and data you use, the better the model performance. We’ve learned that when trained well, a smaller model can yield similar results of a model ten times its size. SLMs are also really good for privacy, sensitive data never needs to leave your device. However, the decision to choose an LLM vs a SLM depends on the use case. You have to factor in things such as device size, budget constraints, privacy regulations, and latency requirements.
The tradeoff is that SLMs are not nearly as resource intensive as LLMs and the inference speed is much faster! This makes them much more accessible to people. Researchers, AI developers and other individuals can explore and experiment with language models without having to invest in multiple GPUs to test out and train models.
The Technical Toolkit for Edge Deployment
So, how do we get these small models onto a phone or a drone? The answer lies in the art of model compression.
The two most critical techniques are Quantization and Knowledge Distillation.
Quantization is a technique to reduce the computational and memory costs of running inference. You reduce the precision of the model’s weight from 32-bit floating point to 2 or 4 bit integers. Think of it like compressing a high-resolution photograph (your original, full-size AI model) into a smaller JPEG file (your quantized model). This technique reduces memory footprint with minimal performance loss, which is really good for devices with very low memory storage.
Knowledge Distillation is where we train a small “student” model to perfectly mimic the output of a massive “teacher” model through knowledge and performance transference. The goal is for the small model to pick up the large models thought process to help it with reasoning.
And while we are here, let’s talk about how SLMs and edge devices shift MLOps: which is the framework for deploying and managing machine learning models. We are moving from a model-centric MLOps to a more hardware-aware MLOps. It’s no longer enough to just version and deploy your model; you must optimize its inference for a specific hardware target. This means leveraging specialized silicon—the Neural Processing Units (NPUs), and the TPUs, which are now embedded in everything from smartphones to smart cars.
Let’s look at a few real-world examples that use SLMs:
US Open’s editorial team actually used Granite models to summarize match insights and add captions to their video content, which increased their productivity by 300%.
Ferrari used Granite models to create AI-generated race summaries that synthesize telemetry, weather and strategy data into compelling narratives in a tone of voice of the fan’s choosing.
Microsoft uses their own Phi models for some versions of Copilot.
Samsung and Salesforce leverage SLMs as well.
Architectural Innovation: Beyond the Transformer
Now, let’s talk a little bit about edge AI architecture. As we know, most language models use The Transformer architecture. While useful, it does have its flaws and one of them exists in its self-attention mechanism(weighs the relevance of those words amongst one another). This is brilliant for reasoning but creates an efficiency bottleneck because its computational cost grows quadratically(exponentially) with the length of the input that is given.
A cutting edge alternative comes from Liquid AI with their Hyena-Edge architecture. It replaces self-attention with a convolution-based multi-hybrid structure, achieving sub-quadratic complexity—closer to linear scaling. This is a fundamental architectural change designed from the ground up for efficiency.
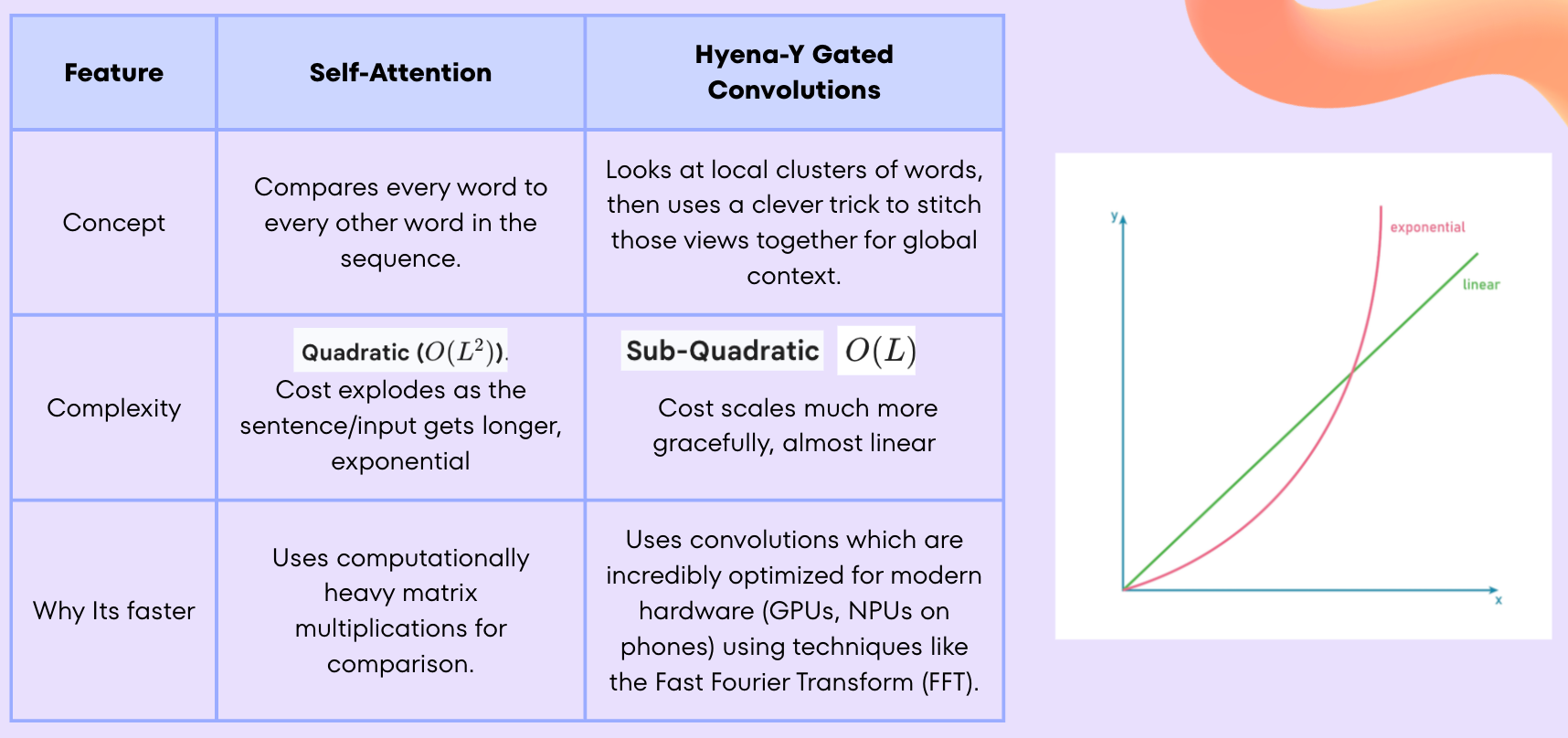
This architecture responds about 30% faster and requires less memory usage. That’s great results considering that every millisecond and every milliwatt counts in the world of edge computing.
The Hyper-Local Future
This brings us to the future. The first frontier is Decentralization through Federated Learning on SLMs.
Federated learning allows multiple parties to collaborate on training machine learning models without sharing their raw, private data. The parties could be individual smartphones, other devices, or separate organizations (like healthcare or businesses). It all works through a central server where the global model sits and then the individual clients/devices interact with it.
Local Training: The client trains the model locally using its own private data (e.g., local health records, medicine supply inventory). The raw data never leaves the organization. The model learns from this private data, and its parameters are slightly adjusted.
Central Aggregation: The client sends only the model updates (the parameter changes, often encrypted) back to the Central Server, not the raw data. The Central Server receives updates from hundreds or thousands of clients. It uses an algorithm (most commonly Federated Averaging) to combine these individual updates into a single, comprehensive update, creating a New, Improved Global Model.
This is a great solution for data privacy and personalization, allowing SLMs to continuously learn and adapt to you without compromising your security. So not only is this useful for hospitals it can be useful for smart cars that need better driving standards that match their unique location, or smartphones that better adapt to your own language/vernacular to improve autocorrect and suggestions.
The second frontier is Hyper-Local Intelligence. This involves combining Multi-Modal SLMs with edge devices to unlock on-device AI agents.
For instance, imagine a construction worker can use some AR safety glasses or a smartphone to help them understand how to use equipment. They’d point the device at the equipment, the visual part of the model will use image recognition to identify what the part is, pick up the audio from the worker asking what is this, then refer to its knowledge from the manual it was trained on plus SLMs to generate instructions for the worker.
Or imagine designing a smartphone workflow that manages your travel information. You’ll tell your phone to put a hotel confirmation screenshot and text with your flight number in your travel photo. The model will analyze the photo and text, parse the hotel name, the dates, and flight information, then use the SLM agents to create a workflow that creates a new folder, adds calendar entries for the flight and hotel, and sets travel alarms for you.
This is the future of autonomous, personalized computing.
The Final Frontier: Neuromorphic Hardware
Finally, the hardware. The ultimate substrate for this future is Neuromorphic Computing.
Chips like IBM’s NorthPole, Loihi by Intel, and NeuronFlow from GrAI Matter Labs are designed to mimic the structure and function of the human brain, focusing on ultra-low power, event-driven processing. These chips are the ideal home for highly sparse and efficient SLMs, pushing AI to the smallest IoT sensors. The vision is AI that runs on milliwatts of power, everywhere, making the cloud optional, not mandatory.
Conclusion: The Ubiquitous AI Future
The future of AI is not just big, it’s small, fast, and local. The reward is building truly ubiquitous, personalized, and privacy-preserving AI. The cloud is optional. The edge is inevitable. With that being said, SLMs and Edge AI is even more nascent than LLMs, so there is lots to be worked on when it comes to observability from a network perspective(devices with little to no connectivity). The need for high accuracy is high as well, which means SLMs need to handle for class labeling and transparency.
Also, you can access my slides at this link!
Killer breakdown of the scaling law rebuttal. The Hyena-Edge architecture's sub-quadratic complexity really changes the game for inference cost at teh edge, but I wonder if the challenge shifts from raw compute to the MLOps infrastucture for managing thousands of device-specific model variants. Federated learning sounds great in theory but coordinating updates across heterogenous hardware without version drift seems brutal.